PredictTheWinner [source code]
public class PredictTheWinner {
static
/******************************************************************************/
class Solution {
Map<String, Integer> map = new HashMap<>();
public boolean PredictTheWinner(int[] nums) {
int sum = 0;
for (int i : nums)
sum += i;
return 2 * getFirstMax(nums, sum, 0, nums.length - 1) >= sum;
}
public int getFirstMax(int[] nums, int sum, int start, int end) {
String s = serialize(nums, start, end);
if (map.containsKey(s))
return map.get(s);
if (start == end)
return nums[start];
int res = 0, n = s.length();
int takeHead = sum - getFirstMax(nums, sum - nums[start], start + 1, end);
int takeTail = sum - getFirstMax(nums, sum - nums[end], start, end - 1);
res = Math.max(takeHead, takeTail);
map.put(s, res);
return res;
}
public String serialize(int[] nums, int start, int end) {
StringBuilder sb = new StringBuilder();
for (int i = start; i <= end; i++)
sb.append('-' + nums[i]);
sb.deleteCharAt(0);
return sb.toString();
}
}
/******************************************************************************/
public static void main(String[] args) {
PredictTheWinner.Solution tester = new PredictTheWinner.Solution();
int[][] inputs = {
{1,5,233,7}, {1},
};
for (int i = 0; i < inputs.length / 2; i++) {
int[] nums = inputs[2 * i];
boolean ans = inputs[1 + 2 * i][0] == 1;
System.out.println(Printer.separator());
boolean output = tester.PredictTheWinner(nums);
System.out.println(
Printer.wrapColor(Printer.array(nums), "magenta") +
" -> " + output +
Printer.wrapColor(", expected: " + ans, ans == output ? "green" : "red")
);
}
}
}
首先, 看这一句:
You can assume each player plays to maximize his score.
这一句的意思不是说每一个player在每一个move就一定选较大的那个end, 而是整体上maximize; 也就是说这个题目不是用一个greedy的思路去做; 想想也知道是这样, 不然这个题目也太trivial了; 这个好歹还是Google的题目;
另外, 看这里题目的win到底是怎么定义的?
predict whether player 1 is the winner.
看起来这个的定义的意思好像是判断1P是不是never lose, 但是你在看下面的描述:
player 1 will never be the winner
you need to return True representing player1 can win
所以最后实际上要你判断的是1P possible to win. 这个跟前面有一个题目还是挺类似的, 就是题目措辞有点模糊; 结果最后两个题目要你判断的其实都是existence of at least one win-path for 1P, 更具体的讲, 也就是判断canWin. 这个需求好像大量出现在下棋的题目里面;
另外, 下棋的题目里面DP基本上是非常常见的操作了, 这题就算没有tag的提示也应该想到;
另外之前flip game的题目的时候好像学到一个game theory的做法, 感觉好像可以用到这里, 但是不确定; 先不管那个了, DP这种做法才是你真实面试的时候应该deliver的做法;
另外, 前面也讲过, 为了实现DP, 就要实现memo, 那么在recursion的参数表的设计上面往往就有讲究; 如果要同时保证mutability, 以及方便作为memo的key, 我的想法是只能用StringBuilder了, 但是这样每一个iteration开始要有一个转化为string的操作, 担心有点浪费时间, 想了一下, 或许可以用Bottom-Up的方法来做? 好像不太好做, 因为不知道base case在哪里. 对于某一个game path, 你不知道最后一个element在哪里, 那么你其实也就是不知道base case在哪里;
最后想了一下只好用Top-Down来做了; //不需要StringBuilder, 直接用string做就行了;
if (!canWin(sb.deleteCharAt(0), n - 1) || !canWin(sb.deleteCharAt(n - 1), n - 1))
如果这样用StringBuilder来做, 反而会出问题, 因为走到第二个case的时候, 其实sb已经被delete两次了;
本来对这道题目也是有点放弃希望了, 而且还花了很长的时间, 结果最后还是做出来了; 速度是25ms (29%), 差强人意吧.
这个题刚开始就根据最简单的下棋游戏的思路, 认准了你输我就赢的DP Property, 来设计, 自然的就认为直接recursive返回值是一个boolean: can win or not; 但是后来发现这个DP问题并没有那么简单. 有时候, 看起来好像desired value有DP Property, 不代表就可以直接确定用这个target value作为recursive返回值; 这里就是这个问题, 如果你直接用canWin这个boolean作为返回值, 你可以发现, you lose I win的这个性质并不成立: 1是我win, 但是12还是我win, 124还是我win;
所以这里的recursive返回值还是要重新找; 这个情况的recursion严格来说前面也不是说就没有碰到过, 就是这种返回值要绕一个弯的题目; 之前总结过, 这种intermediate recursive return value的获得, 一般有两种思路:
- root participation
- greedy value
这题, 其实要用到的就是第二种思路; 这个题目本身你可以看到就是抢数字的游戏, 最后谁抢到的价值多谁就赢. 那么winning condition是什么? 其实换一个角度来理解, 就是你是否能抢到至少一半的value;
理解了这个之后, 这个问题的设计就不难了; 一个遗留的问题是, 怎么选择memo的key(也就是以前常说的表格的index)? 最直接的想法还是string. 但是这个string你要有一个技巧, 就是要假如separator, 不然有些数字有多digit, 就会出问题;
另外, 这个题目我一开始是准备让整个参数表完全用string来代表, 但是后来发现这个思路很麻烦, 因为就算这个string是加了separator的, 那么最后你重新需要get head和tail的时候, 还需要重新parse, 比如"233-1-1", 你get head的时候就很麻烦; 所以我最后决定input直接用int array本身来做, 然后另外加一个serialize的功能, 用来查表; 这个方法还有另外一个需要的点是, 你的subproblem怎么实现? 一个简单的做法是用Arrays.copyOfRange()来制作下一个level的input array, 但是有必要吗? 只有在string是input的时候, 我们才需要用sub copy的思路, 在array作为input的时候, 直接用index就可以了!
上面的做完, 就得到了我的第一个AC版本; 但是string的这个serialization的操作的cost还是很让人心疼; 然后我又想到了一个问题, 既然已经决定用array本身作为input, 其实我们根本没有必要用serialization来做memo key! 直接用两个边界index来做就行了; 这两个int组合成一个unique的int, 就可以用来查表了; 最后得到这个ver2:
class Solution {
Map<Integer, Integer> map = new HashMap<>();
public boolean PredictTheWinner(int[] nums) {
int sum = 0;
for (int i : nums)
sum += i;
return 2 * getFirstMax(nums, sum, 0, nums.length - 1) >= sum;
}
public int getFirstMax(int[] nums, int sum, int start, int end) {
int key = start * 100 + end;
if (map.containsKey(key))
return map.get(key);
if (start == end)
return nums[start];
int res = 0;
int takeHead = sum - getFirstMax(nums, sum - nums[start], start + 1, end);
int takeTail = sum - getFirstMax(nums, sum - nums[end], start, end - 1);
res = Math.max(takeHead, takeTail);
map.put(key, res);
return res;
}
}
速度是12(31), 速度其实提升很大, 直接砍了一半, 但是percentile却没有怎么提升, 感觉应该是我这个算法本身核心思路还不够优越;
受到下面submission最优解的启发, 继续优化:
class Solution {
public boolean PredictTheWinner(int[] nums) {
int[][] memo = new int[nums.length][nums.length];
int sum = 0;
for (int i : nums)
sum += i;
return 2 * getFirstMax(nums, sum, 0, nums.length - 1, memo) >= sum;
}
public int getFirstMax(int[] nums, int sum, int start, int end, int[][] memo) {
if (memo[start][end] > 0)
return memo[start][end];
if (start == end)
return nums[start];
int res = 0;
int takeHead = sum - getFirstMax(nums, sum - nums[start], start + 1, end, memo);
int takeTail = sum - getFirstMax(nums, sum - nums[end], start, end - 1, memo);
res = Math.max(takeHead, takeTail);
memo[start][end] = res;
return res;
}
}
这下到了6(55), 算是最优解了;
另外, 虽然这一题跟前面的flip game有不少区别, 但是也有很多的相似之处; 这些similarity在大部分的下棋题目里面都通用. 最重要的一个是:
Always in the perspective of 1P
所有的这些题目, 你的recursion函数, 当前level对应的都是1P, 无论是你判断canWin, 还是这里的getMax, 都是针对当前这个棋盘的1P而言的;
当然, 如之前flip game的时候说过的, 你如果一定要手动去用一个flag来记录turn, 是可以的, 但是到目前位置我还没有碰到过always 1P没有办法解决的题目, 所以我觉得还是继续沿用这个思路比较靠谱, 因为用这个思路做出来的算法有两大优势:
- 简单好理解, 只需要站在recursive的角度就能理解;
- 容易形成memo;
这个是submission最优解:
class Solution {
// memoized search
public boolean PredictTheWinner(int[] nums) {
if(nums == null || nums.length == 0){
return true;
}
int n = nums.length;
int[][] memo = new int[n][n];
int sum = 0;
for(int i = 0; i<n; i++){
sum += nums[i];
}
return sum <= 2 * maxofFirst(memo, nums, 0, n-1);
}
private int maxofFirst(int[][] memo, int[] nums, int start, int end){
if(start == end){
return nums[start];
}
if(start + 1 == end){
return Math.max(nums[start], nums[end]);
}
if(memo[start][end] > 0){
return memo[start][end];
}
memo[start][end] = Math.max(nums[start] + Math.min(maxofFirst(memo, nums, start+1, end-1), maxofFirst(memo, nums, start+2, end)), nums[end] + Math.min(maxofFirst(memo, nums, start+1, end-1), maxofFirst(memo, nums, start, end-2)));
return memo[start][end];
}
}
这个解最后的速度是6(55), 比我的ver2还要快一倍! 实际上他的核心原理还是跟我的一样的, 之所以能够比我的快这么多, 是因为他memo的实现想到了用array来做; 这个我真的是差了最后一步: 已经想到用两个index来作为key了, 没有想到直接用一个matrix来记录算了; 当然最后仅仅是因为我用了HashMap, 就速度差这么多, 也是有点夸张的;
另外一个submission最优解: 5(85):
class Solution {
public boolean PredictTheWinner(int[] nums) {
int n = nums.length;
if (n % 2 == 0) return true;
if (n == 1) return true;
int[][] dp = new int[n][n]; // dp[i][j]: max diff the first player to pick can get from nums[i -> j]
for (int i = 0; i < n; i++) {
dp[i][i] = nums[i];
}
for (int len = 1; len < n; len++) {
for (int i = 0; i + len < n; i++) {
int low = i, high = i + len;
dp[low][high] = Math.max(nums[low] - dp[low + 1][high], nums[high] - dp[low][high - 1]);
}
}
return dp[0][n - 1] >= 0;
}
}
基本就是Bottom-Up的写法; 但是有几个区别:
- 注意这里表格的size: 没有+1, 因为这里的表格的index就是nums本身的index, 大家都是0-based的, 没有必要+1;
- iterate on sub len: 这个以前是见到过的;
- 这里他memo表格的entry的定义跟我的并不一样, 并不是单纯的firstMax, 而是一个diff; 反正也行吧, 其实都差不多;
这个是editorial里面一个可以佐证always 1P的论述:
Since both the players are assumed to be playing smartly and making the best move at every step, both will tend to maximize their scores. Thus, we can make use of the same function winner to determine the maximum score possible for any of the players.
这个还是有道理的, always 1P思路成立的一个前提是两个选手的策略是一样的;
另外, 一个很简单的问题, 这个问题为什么greedy不行? 因为你始终在两个end当中挑较大的一个的话, 最后真正假如有一个特别大的藏的比较深, 你就可能轮不到了;
这个是Minimax算法的介绍, 好像有点意思, 值得看一下;
Minimax (sometimes MinMax or MM[1]) is a decision rule used in decision theory, game theory, statistics and philosophy for minimizing the possible loss for a worst case (maximum loss) scenario. When dealing with gains, it is referred to as "maximin" - to maximize the minimum gain. Originally formulated for two-player zero-sum game theory, covering both the cases where players take alternate moves and those where they make simultaneous moves, it has also been extended to more complex games and to general decision-making in the presence of uncertainty.
editorial1就是基于这个算法:
Further, note that the value returned at every step is given by
turn*max(turn*a,turn*b). This is equivalent to the statementmax(a,b)for Player 1's turn andmin(a,b)for Player 2's turn.
This is done because, looking from Player 1's perspective, for any move made by Player 1, it tends to leave the remaining subarray in a situation which minimizes the best score possible for Player 2, even if it plays in the best possible manner. But, when the turn passes to Player 1 again, for Player 1 to win, the remaining subarray should be left in a state such that the score obtained from this subarrray is maximum(for Player 1).
This is a general criteria for any arbitrary two player game and is commonly known as the Min-Max algorithm.
public class Solution {
public boolean PredictTheWinner(int[] nums) {
return winner(nums, 0, nums.length - 1, 1) >= 0;
}
public int winner(int[] nums, int s, int e, int turn) {
if (s == e)
return turn * nums[s];
int a = turn * nums[s] + winner(nums, s + 1, e, -turn);
int b = turn * nums[e] + winner(nums, s, e - 1, -turn);
return turn * Math.max(turn * a, turn * b);
}
}
具体还是要自己看editorial: https://leetcode.com/articles/predict-the-winner/; 介绍的其实是比较好的; 这个算法虽然是editorial的守门员, 但是一点都不trivial;
注意, 这里这个turn并不是单纯的我之前说的那个turn flag的作用, 这里真正区分两个player的其实是winner这个函数的返回值的正负号; 正号代表score in favor of 1P, 负号反之; 理解了这个地方之后, 可以看到整个代码其实写的非常concise and consistent; 这个代码虽然我现在大体能看懂了, 但是感觉这背后的巧妙性并没有完全的体会到; 可能还是要看一下那个miniamx算法之后才能理解到底是什么一回事, 尤其是怎么想到这样设计这个算法, 包括这个turn的设计, 这样一个看起来是turn, 但是却又实际参与运算的参数, 到底是怎么想到设计进去的;
这个是作者自己用的图像: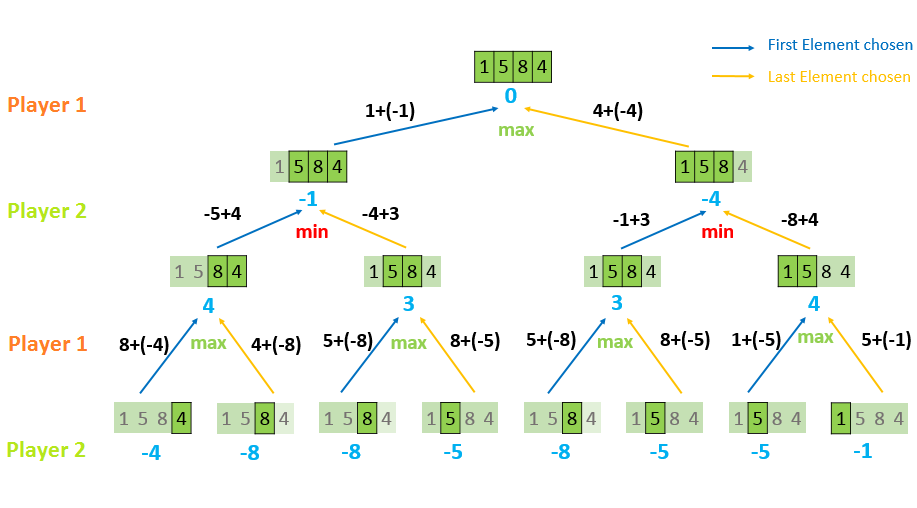
另外, 接着作者的话说, 怎么理解最后的这个return turn * Math.max(turn * a, turn * b);. 首先有一点要说一下, 这里的这个作者虽然说了一个1P's perspective, 但是这里的这个手段跟我自己总结的always 1P其实是有一点差别的; 首先, 这里在分析的时候确实是始终站在1P的角度去分析, 但是这个1P perspective的定义不一样, 这里的1P perspective是正号, 所以如果你一个结果想要tilt in favor of 1P, 你应该怎么做?
另外, 之所以看出来这里winner返回值的正号对应的是1P是因为这个: return winner(nums, 0, nums.length - 1, 1) >= 0, 所以最后就是要看这个大winner的返回值是不是正号, 再回顾我们题目一开始的需求, 就不难理解了;
我们前面其实已经说过, 这个题目里面是有明确的1P和2P的概念的区分的, 而不是跟我自己的做法那样, 直接就是, 实际上, 我自己的做法, 根本没有player's perspective, 只有input's perspective; 你的recursion函数最后返回的是一个独立于任何一个player的结果, 至于最后某一个player自己是什么结果, 只要到时候对应知道他摊到的是什么input就行了;
这个MM算法反过来, 则有明确的player的概念: winner的返回值定义的其实就类似于一个胜利的天平的东西; 首先, 一个iteration, 你的input是什么, 是包括一个sub, 和一个turn的; 对于同样的一个sub, 如果是1P的turn, 我们有一种结果(玩法), 如果是2P的turn, 我们又有另外一种玩法;
所以实际上, 对于一个iteration(一个sub, 一个turn), 这个winner函数的返回值, 其实就是你能够得到的最大正值. 你可能会问, 为什么就只想正值? 这个就跟学逻辑表达式的时候, 只考虑true很类似的;
Now, at every step of the recursive process, we determine the maximum score possible for the current player. It will be the maximum one possible out of the scores obtained by picking the first or the last element of the current subarray.
To obtain the score possible from the remaining subarray, we can again make use of the same winner function and add the score corresponding to the point picked in the current function call. But, we need to take care of whether to add or subtract this score to the total score available. If it is Player 1's turn, we add the current number's score to the total score, otherwise, we need to subtract the same.
理解了这个之后, return turn * Math.max(turn * a, turn * b)这个应该就不难理解了; 一个sub给你, 如果是我自己的turn(有正向继续加深的机会), 那么我们选择我自己take s, or take e, 并且加上recurse下去回来之后的最大正值; 得到的两种结果当中最大的, 就是我的要的, 这个就是maximize gain的过程, 很正常; 但是如果这个turn不是我自己的, 怎么办? 也就是是2P的turn: 那么这个时候a就代表lose s to 2P, b代表lose e to 2P, 然后两者分别加上recurse上来的结果; 下面一个比较难理解的是, 这样的a,b, 为什么我们要返回min? 这个的话, 稍微看看上面的图片是有所帮助的; 好像还是不太好理解; 当然你也可以说, 2P也要maximize自己的机会, 所以尽量把胜利的天平往负号方向扳. 不过这个是建立在一个人类逻辑的基础上, 你可以利用人逻辑去学习一个算法, 但是你不能指望一个算法本身就是去复制/学习一个人逻辑, 这里编的就是一个普通的满足一个需求的算法, 不是人工智能;
但是仔细想了一下, 这个算法, 除了用这个角度来理解, 真的没有办法理解了, 只能认为两个玩家, 分别都是play to the maximum of his own benefit; 只有这样, 在2P的turn的时候, 才会直接选择min, 因为这样可以让胜利的天平向2P自己的方向(负号方向)多倾斜一些; 但是感觉这个解释还是太牵强了.
关于这个, 对应的就是一开始的:
Since both the players are assumed to be playing smartly and making the best move at every step, both will tend to maximize their scores. Thus, we can make use of the same function winner to determine the maximum score possible for any of the players.
另外, 这个正负号的解释, 其实他一开始给了一点说明:
The idea behind the recursive approach is simple. The two players Player 1 and Player 2 will be taking turns alternately. For the Player 1 to be the winner, we need scorePlayer_1≥scorePlayer_2. Or in other terms, scorePlayer_1−scorePlayer_2≥0
这个还是挺说得通的; 这样也就解释了为什么1P的贡献是正, 而2P的贡献是负;
感觉还是有点没把握, 不过贴一下Wiki上面关于MM算法的解释:
The maximin value of a player is the largest value that the player can be sure to get without knowing the actions of the other players; equivalently, it is the smallest value the other players can force the player to receive when they know his action.
Calculating the maximin value of a player is done in a worst-case approach: for each possible action of the player, we check all possible actions of the other players and determine the worst possible combination of actions - the one that gives player i the smallest value. Then, we determine which action player i can take in order to make sure that this smallest value is the largest possible.
所以这题的这个winner的返回值其实就是这个maximin值, 也就是我们自己解释的时候说的max possible score;
editorial1没有应用memo, 一个可能的原因是因为没有使用always 1P的方法. 但是仔细想想, 如果真的想要使用memo, 这里的参数表好像也可以? 只要保证memo表格有三个维度就行了; 不过一个问题是, 因为维度太多, 所以这样做出来的表格, 最后的查表的hit概率会比较低: 因为每一个entry涵盖的内容太specific, 所以导致最后entry与entry之间overlapping的概率太低, 而这个overlapping才是DP一开始能够完成加速的根本原因;
为了降低memo表格的维度, 最后在editorial2当中, turn这个维度被舍弃掉了, 同时应用always 1P思路来进行适当的改写, 最后就可以采用memo了:
public class Solution {
public boolean PredictTheWinner(int[] nums) {
Integer[][] memo = new Integer[nums.length][nums.length];
return winner(nums, 0, nums.length - 1, memo) >= 0;
}
public int winner(int[] nums, int s, int e, Integer[][] memo) {
if (s == e)
return nums[s];
if (memo[s][e] != null)
return memo[s][e];
int a = nums[s] - winner(nums, s + 1, e, memo);
int b = nums[e] - winner(nums, s, e - 1, memo);
memo[s][e] = Math.max(a, b);
return memo[s][e];
}
}
同样, 注意这里memo表格的size没有+1;
We can omit the use of turn to keep a track of the player for the current turn. To do so, we can make use of a simple observation. If the current turn belongs to, say Player 1, we pick up an element, say x, from either end, and give the turn to Player 2. Thus, if we obtain the score for the remaining elements(leaving x), this score, now belongs to Player 2. Thus, since Player 2 is competing against Player 1, this score should be subtracted from Player 1's current(local) score(x) to obtain the effective score of Player 1 at the current instant.
大概意思是, 所谓的正负号你考虑的更应该是针对当前的这个input来考虑, 而不是始终想着是哪个player;
editorial2就是Bottom-Up:
public class Solution {
public boolean PredictTheWinner(int[] nums) {
int[][] dp = new int[nums.length + 1][nums.length];
for (int s = nums.length; s >= 0; s--) {
for (int e = s + 1; e < nums.length; e++) {
int a = nums[s] - dp[s + 1][e];
int b = nums[e] - dp[s][e - 1];
dp[s][e] = Math.max(a, b);
}
}
return dp[0][nums.length - 1] >= 0;
}
}
当然, 跟我的解法的Bottom-Up还是有一点区别的; 首先注意他这里表格的大小, 两个维度不是一样大的; 其次注意最外层循环的范围和顺序; 范围是从n开始, 因为表格第一维的长度是n+1, 他这里估计就是想从最边缘的开始计算; 以前上课的时候老师说过, 这种Bottom-Up建表的时候两个重要的地方:
- proper initialization
- iteration order
这里他这样处理, 是为了避免需要单独处理init; 事实上, 我把他的s的起点改成n-1, 照样还是AC, 因为这个iteration其实是被跳掉了(因为下面的e一个legal value都没有); 但是他还是愿意这样写, 反正最后结果是一样的;
在来说order, 因为这个题目, 需要表达的是一个longer sub depends on shorter sub; 所以这里他就是按照这个order来建表: 要保证一个entry被查的时候已经填好了; 前面用过的一个思路是iteration on sub length; 这里还是直接给两个端点来iterate; 更简单的理解:
int a = nums[s] - dp[s + 1][e];
int b = nums[e] - dp[s][e - 1];
可以看到, 在某一个[s][e]的时候, 我们需要的是[s+1]和[e-1]的entry, 所以要保证[s+1] before [s], [e-1] before [e], 这样你iteration的顺序就很清晰了; 这个order的控制, 说到底还是由你的recursive表达式的计算来决定的;
另外, 这里虽然是用两个端点来iterate, 但是好像并没有刻意的去控制关于subarray这个概念本身; 真正最后体现这个概念的其实就是一个e starts from s + 1这一点, 这样保证s和e可以组合成一个subarray就可以了; 另一个角度, 也可以提供一个广义的iterate subarray的思路给你, 尤其是需要iterate by index的时候: 直接iterate on start就行了, 控制end的下限, 就可以保证the two indices always corresponds to a legal and unique subarray; 这样一个轻量化的控制的好处是, 我们就可以不用纠结于subarray这个概念, 而是直接从recursive表达式里面获得一个可行的order, 然后直接adapt subarray这个概念就行了;
editorial4是在以上的基础上继续降低空间占用到O(N):
public class Solution {
public boolean PredictTheWinner(int[] nums) {
int[] dp = new int[nums.length];
for (int s = nums.length; s >= 0; s--) {
for (int e = s + 1; e < nums.length; e++) {
int a = nums[s] - dp[e];
int b = nums[e] - dp[e - 1];
dp[e] = Math.max(a, b);
}
}
return dp[nums.length - 1] >= 0;
}
}
Thus, for filling in any entry in dp array, only the entries in the next row(same column) and the previous column(same row) are needed.
所以最后这里干脆只维护一个row就行了; 注意, 这里参与[e]的计算是[e]和[e-1], 这个看起来好像有点乱, 但是如果实在不行, 你可以当成两行来看待:
... e ... //new
... e-1 e ... //old
这样应该稍微好帮助理解一些;
这个是discussion最优解, 其实类似editorial的解法, 核心计算还是计算(1P - 2P), 不过不是按照editorial1那样死板的1P, 2P的规定和定义, 而是类似for a particular input, return the maximum possible 1P - 2P where 1P is the first-in-action player for this particular input;
@odin said in JAVA 9 lines DP solution, easy to understand with improvement to O(N) space complexity.:
The dp[i][j] saves how much more scores that the first-in-action player will get from i to j than the second player. First-in-action means whomever moves first. You can still make the code even shorter but I think it looks clean in this way.
public boolean PredictTheWinner(int[] nums) {
int n = nums.length;
int[][] dp = new int[n][n];
for (int i = 0; i < n; i++) { dp[i][i] = nums[i]; }
for (int len = 1; len < n; len++) {
for (int i = 0; i < n - len; i++) {
int j = i + len;
dp[i][j] = Math.max(nums[i] - dp[i + 1][j], nums[j] - dp[i][j - 1]);
}
}
return dp[0][n - 1] >= 0;
}
111
> Here is the code for O(N) space complexity:
```java
public boolean PredictTheWinner(int[] nums) {
if (nums == null) { return true; }
int n = nums.length;
if ((n & 1) == 0) { return true; } // Improved with hot13399's comment.
int[] dp = new int[n];
for (int i = n - 1; i >= 0; i--) {
for (int j = i; j < n; j++) {
if (i == j) {
dp[i] = nums[i];
} else {
dp[j] = Math.max(nums[i] - dp[j], nums[j] - dp[j - 1]);
}
}
}
return dp[n - 1] >= 0;
}
Edit : Since I have some time now, I will explain how I come up with this solution step by step:
1, The first step is to break the question into the sub-problems that we can program. From the question, the winning goal is that "The player with the maximum score wins". So one way to approach it is that we may want to find a way to maximize player 1's sum and check if it is greater than player 2's sum (or more than half of the sum of all numbers). Another way, after noting that the sum of all numbers is fixed, I realized that it doesn't matter how much player 1's total sum is as long as the sum is no less than player 2's sum. No matter how, I think we can easily recognize that it is a recursive problem where we may use the status on one step to calculate the answer for the next step. It is a common way to solve game problems. So we may start with using a brutal force recursive method to solve this one.
2, However, we always want to do better than brutal force. We may easily notice that there will be lots of redundant calculation. For example, "player 1 picks left, then player 2 picks left, then player 1 picks right, then player 2 picks right" will end up the same as "player 1 picks right, then player 2 picks right, then player 1 picks left, then player 2 picks left". So, we may want to use dynamic programming to save intermediate states.
3, I think it will be easy to think about using a two dimensional array dp[i][j] to save all the intermediate states. From step 1, we may see at least two ways of doing it. It just turned out that if we choose to save how much more scores that the first-in-action player will earn from position i to j in the array (as I did), the code will be better in a couple of ways.
4, After we decide that dp[i][j] saves how much more scores that the first-in-action player will get from i to j than the second player, the next step is how we update the dp table from one state to the next. Going back to the question, each player can pick one number either from the left or the right end of the array. Suppose they are picking up numbers from position i to j in the array and it is player A's turn to pick the number now. If player A picks position i, player A will earn nums[i] score instantly. Then player B will choose from i + 1 to j. Please note that dp[i + 1][j] already saves how much more score that the first-in-action player will get from i + 1 to j than the second player. So it means that player B will eventually earn dp[i + 1][j] more score from i + 1 to j than player A. So if player A picks position i, eventually player A will get nums[i] - dp[i + 1][j] more score than player B after they pick up all numbers. Similarly, if player A picks position j, player A will earn nums[j] - dp[i][j - 1] more score than player B after they pick up all numbers. Since A is smart, A will always choose the max in those two options, so:
dp[i][j] = Math.max(nums[i] - dp[i + 1][j], nums[j] - dp[i][j - 1]);5, Now we have the recursive formula, the next step is to decide where it all starts. This step is easy because we can easily recognize that we can start from dp[i][i], where dp[i][i] = nums[i]. Then the process becomes a very commonly seen process to update the dp table. I promise that this is a very useful process. Everyone who is preparing for interviews should get comfortable with this process:
Using a 5 x 5 dp table as an example, where i is the row number and j is the column number. Each dp[i][j] corresponds to a block at row i, column j on the table. We may start from filling dp[i][i], which are all the diagonal blocks. I marked them as 1. Then we can see that each dp[i][j] depends only on dp[i + 1][j] and dp[i][j - 1]. On the table, it means each block (i, j) only depends on the block to its left (i, j - 1) and to its down (i + 1, j). So after filling all the blocks marked as 1, we can start to calculate those blocks marked as 2. After that, all blocks marked as 3 and so on.
So in my code, I always use len to denote how far the block is away from the diagonal. So len ranges from 1 to n - 1. Remember this is the outer loop. The inner loop is all valid i positions. After filling all the upper side of the table, we will get our answer at dp[0][n - 1] (marked as 5). This is the end of my code.
However, if you are interviewing with a good company, they may challenge you to further improve your code, probably in the aspect of space complexity. So far, we are using a n x n matrix so the space complexity is O(n^2). It actually can be improved to O(n). That can be done by changing our way of filling the table. We may use only one dimensional dp[i] and we start to fill the table at the bottom right corner where dp[4] = nums[4]. On the next step, we start to fill the second to the last line, where it starts from dp[3] = nums[3]. Then dp[4] = Math.max(nums[4] - dp[3], nums[3] - dp[4]). Then we fill the third to the last line where dp[2] = nums[2] and so on... Eventually after we fill the first line and after the filling, dp[4] will be the answer.
On a related note, whenever we do sum, subtract, multiply or divide of integers, we might need to think about overflow. It doesn't seem to be a point to check for this question. However, we may want to consider using long instead of int for some cases. Further, in my way of code dp[i][j] roughly varies around zero or at least it doesn't always increases with approaching the upper right corner. So it will be less likely to overflow.

底下一堆解释的东西, 没有仔细看了;
这个人的O(N)空间解法里面应用了一个重要的优化: 如果nums的长度是偶数, 那么1P一定会赢, 这个很奇葩, 但是也有人证明了;
@MichaelPhelps said in JAVA 9 lines DP solution, easy to understand with improvement to O(N) space complexity.:
@Mr.Bin
Actually, this is quite straightforward. If you compute the sums of the odd elements and the even elements respectively, there will be 2 situations S_odd >= S_even or S_odd < S_even.
All the numbers are known to both players at the beginning, the 1st player has the priority to pick and he can easily figure out which sum is bigger. If S_even >= S_odd, the 1st player can always pick the first element (0 indexed) in the array, the 2nd player, however, has NO choice but pick either side and both are odd elements marked as 'O' in the original array. By repeating this process the 1st player will always win if we count tie is a win for the 1st player. Same thing if S_odd >= S_even as the first player just need to pick the last element in the array at the first move.
0 1 2 3 ... 2n - 2 2n-1 ( 2n elements)
E O E O ... E OHope this helps.
discussion另外一个解法, 好像是MIT的一个什么公开课里面教的东西:
@kevin36 said in DP O(n^2) + MIT OCW solution explanation:
The idea is that this is a minimax game, and if you went to MIT and took 6.046 then you would have seen something similar to this problem in class. And thanks to MIT OCW everyone can see the explanation
The DP solution
```c++
class Solution {
public:
bool PredictTheWinner(vector
if(nums.size()% 2 == 0) return true;
int n = nums.size();
vector<vector<int>> dp(n, vector<int>(n, -1));
int myBest = utill(nums, dp, 0, n-1);
return 2*myBest >= accumulate(nums.begin(), nums.end(), 0);
}
int utill(vector<int>& v, vector<vector<int>> &dp, int i, int j){
if(i > j) return 0;
if(dp[i][j] != -1) return dp[i][j];
int a = v[i] + min(utill(v,dp, i+1, j-1), utill(v, dp, i+2, j));
int b = v[j] + min(utill(v,dp,i, j-2), utill(v,dp, i+1, j-1));
dp[i][j] = max(a, b);
return dp[i][j];
}
};
下面有人给上面这个视频的总结:
@zzwcsong said in [DP O\(n^2\) \+ MIT OCW solution explanation](https://discuss.leetcode.com/post/164196):
> Thanks for sharing your solution, and the video in MIT OCW is really helpful.
>
> I try to summarize what the video tell us.
>
> The goal here is that we want to maximize the amount of money we can get assuming we move first.
>
>
> Here your dp[i][j] means the max value we can get if it it's our turn and only coins between i and j remain.(Inclusively)
>
> So dp[i][i] means there is only one coin left, we just pick it, dp[i][i+1] means there are only two left, we then pick the max one.
>
> Now we want to derive the more general case. `dp[i][j] = max( something + v[i], something + v[j])`, since we either will pick the i or j coin. The problem now turns to what "something" here will be.
>
> A quick idea may be` dp[i][j] = max( dp[i + 1][j] + v[i], dp[i][j - 1] + v[j])`, but here `dp[i + 1][j]` and `dp[i][j - 1]` are not the values directly available for us, it depends on the move that our opponent make.
>
> Then we assume our opponent is as good as we are and always make optimize move. The worse case is that we will get the minimal value out of all possible situation after our opponent make its move.
>
> so the correct dp formula would be ` dp[i][j] = max( min (dp[i + 1][j - 1], dp[i + 2][ j]) + v[i], min (dp[i][j - 2], dp[i + 1][ j - 1]) + v[j]})` .
> If we pick i, then our opponent need to deal with subproblem `dp[i + 1][j]`, it either pick from i + 2 or j - 1. Similarly, If we pick j, then our opponent need to deal with subproblem `dp[i][j - 1]` , it either pick from i + 1 or j - 2. We take the worse case into consideration so use min() here.
>
> Hope this is helpful, and point out if I make any mistake :-)
---
### Problem Description
Given an array of scores that are non-negative integers. Player 1 picks one of the numbers from either end of the array followed by the player 2 and then player 1 and so on. Each time a player picks a number, that number will not be available for the next player. This continues until all the scores have been chosen. The player with the maximum score wins.
Given an array of scores, predict whether player 1 is the winner. You can assume each player plays to maximize his score.
Example 1:
Input: [1, 5, 2]
Output: False
Explanation: Initially, player 1 can choose between 1 and 2.
If he chooses 2 (or 1), then player 2 can choose from 1 (or 2) and 5. If player 2 chooses 5, then player 1 will be left with 1 (or 2).
So, final score of player 1 is 1 + 2 = 3, and player 2 is 5.
Hence, player 1 will never be the winner and you need to return False.
Example 2:
Input: [1, 5, 233, 7]
Output: True
Explanation: Player 1 first chooses 1. Then player 2 have to choose between 5 and 7. No matter which number player 2 choose, player 1 can choose 233.
Finally, player 1 has more score (234) than player 2 (12), so you need to return True representing player1 can win.
``` Note:
- 1 <= length of the array <= 20.
- Any scores in the given array are non-negative integers and will not exceed 10,000,000.
- If the scores of both players are equal, then player 1 is still the winner.
Difficulty:Medium
Total Accepted:14.7K
Total Submissions:32.9K
Contributor: sameer13
Companies
google
Related Topics
dynamic programming minimax
Similar Questions
Can I Win