FindEventualSafeStates [source code]
public class FindEventualSafeStates {
static
/******************************************************************************/
class Solution {
Boolean[] memo;
public List<Integer> eventualSafeNodes(int[][] graph) {
int N = graph.length;
memo = new Boolean[N];
List<Integer> res = new ArrayList<> ();
for (int i = 0; i < N; i++) {
if (!dfs (i, graph, new boolean[N]))
res.add (i);
}
Collections.sort (res);
return res;
}
boolean dfs (int root, int[][] graph, boolean[] visited) {
if (memo[root] != null)
return memo[root];
boolean res = false;
if (visited[root])
res = true;
else {
visited[root] = true;
for (int neighbor : graph[root]) {
if (dfs (neighbor, graph, visited)) {
res = true;
break;
}
}
visited[root] = false;
}
memo[root] = res;
return res;
}
boolean hasCycle (int root, int[][] graph) {
// TODO: fix this BFS solution
boolean[] visited = new boolean[graph.length];
Queue<Integer> queue = new LinkedList<> ();
queue.offer (root);
visited[root] = true;
while (!queue.isEmpty ()) {
int cur = queue.poll ();
for (int neighbor : graph[cur]) {
if (visited[neighbor])
return true;
visited[neighbor] = true;
queue.offer (neighbor);
}
}
return false;
}
}
/******************************************************************************/
public static void main(String[] args) {
FindEventualSafeStates.Solution tester = new FindEventualSafeStates.Solution();
int[][][] inputs = {
{{1,2},{2,3},{5},{0},{5},{},{}}, {{2,4,5,6}},
{{},{0,2,3,4},{3},{4},{}}, {{0,1,2,3,4}},
};
for (int i = 0; i < inputs.length / 2; i++) {
System.out.println (Printer.separator ());
int[][] graph = inputs[2 * i];
List<Integer> ans = new ArrayList<> (), output = tester.eventualSafeNodes (graph);
for (int num : inputs[2 * i + 1][0])
ans.add (num);
System.out.printf ("%s%s, expected: %s\n",
Matrix.printMatrix (graph), Printer.wrap (output.toString (), output.equals (ans) ? 92 : 91), ans
);
}
}
}
咋一看好像就是detect cycle的感觉; node给的比较多, 好像不好用recursion?
好像单纯的visited不是很容易在这题找到cycle;
https://www.geeksforgeeks.org/detect-cycle-in-a-graph/
要维护path;
一开始最naive的方法直接用visited来维护所有被搜索到的node, 但是这个想法是有问题的, 最后真正的做法应该是维护一个path, 而不是所有被flood到的nodes, 这个也是为什么我一开始的DFS写法什么的是错的;
这个结论要稍微记一下, 因为cycle detection是一个应用场合相当丰富的话题了, 这个东西还是必须要相当熟练的;
上面提示到要维护path的时候, 直接想到干脆用backtrack, 因为自然的维护了path;
BFS应该也是能修改的, 对应的做法应该差不多, 感觉麻烦一点; 可以用set来维护path, add和remove都很快;
最后也是莫名其妙就AC了, 一个重要的优化是加了memo, 这样一个cycle里面只需要走一个node, 就足够了, 最后可以保证每一个node只被访问一次, 这个是有专门的大test来break的, 一开始我也是TLE;
最后回过头来想, 为什么这个memo这么重要? 因为有了这个memo之后, 每一个cycle只会被探索一次! 不会说比如一个很大的cycle, 最后你从当中的每一个node都要出发去探索一次; 这个也就是这题的memo考察的地方; 总体来说这题还是有点考察思维的;
2018-05-01 19:10:41 回头来看这个题目, 感觉读懂题目, 并且读到是cycle问题, 是这个问题的主要难点; 题目描述本身还是有点绕人的;
另外我这里这个DFS设计的返回值好像应该是can not reach sink. 不对, 我返回的其实就是has cycle. 这里我逻辑实际上最后简化了很多了; 只要我这个node无论怎么走, 都走不到cycle, 就是safe的; 这个也是符合题目的意思的, 题目问的不是there is a path to sink, 而是, there is no path to a cycle.
editorial
Approach #1: Reverse Edges [Accepted]
Intuition
The crux of the problem is whether you can reach a cycle from the node you start in. If you can, then there is a way to avoid stopping indefinitely; and if you can't, then after some finite number of steps you'll stop.
Thinking about this property more, a node is eventually safe if all it's outgoing edges are to nodes that are eventually safe.
这个想法很有意思, 因为实际上这个graph最后实际上就是一个被分成了两个partition, safe的和unsafe的; 所以这个其实有点类似一个UF的场景? 不过因为我们没有一个合理的base case: 每一个safe node最后获得的终点可能都不一样, 所以直接使用UF好像并不是那么好写;
严格来说, UF是不好写的, 因为最后实际上整个graph分成的不是两部分, 而是分成很多部分: unsafe的, 也分在不同的cycle里面的; safe的nodes当中, 也分成ends at different sinks的nodes, 所以简单的UF好像真的是不那么容易解决;
This gives us the following idea: we start with nodes that have no outgoing edges - those are eventually safe. Now, we can update any nodes which only point to eventually safe nodes - those are also eventually safe. Then, we can update again, and so on.
哦, 怪我了, 这个是我没想到, 起码unsafe sinks这个base case还是可以找到的; 那么这题实际上感觉UF还是能够做的, 每一个sink独自完成一个union操作就行了? 如果一个node可以到不同的sink怎么办? 那么当你从两个不同的sink同时向这个node出发union的时候, 可能就有重复, 或许可以用memo来解决这个问题;
再想了想, 需要memo吗? 就算比如一个node可以到两个sink, 也就是属于两个不同的group, 又怎么样呢? 我们需要证明的是他至少属于一个有sink的group就行了; 所以如果他属于多个sink的group, 那么只要比如most recently unioned那一个保留就行了;
However, we'll need a good algorithm to make sure our updates are efficient.
Algorithm
We'll keep track of graph, a way to know for some node i, what the outgoing edges (i, j) are. We'll also keep track of rgraph, a way to know for some node j, what the incoming edges (i, j) are.
也就是记录自己的child和parent?
2018-05-01 19:20:51 实际上他最后的算法的思路是有点像UF的; 是一个Bottom-Up的过程, 自然就需要一个incoming edge list这样的结构;
不过这种预处理方法还是记录一下; 一般很熟悉的graph就是简单的adjacency list的表达方式: 每个node记录自己作为tail的edge; 但是对于每一个node, 同时记录自己作为head的edge, 这个实际上是不常见的应用场景; 但是要熟悉这么一个手段, 要是需要用到的时候, 要知道可以很方便的做, 不是什么很expensive的操作;
Now for every node j which was declared eventually safe, we'll process them in a queue. We'll look at all parents i = rgraph[j] and remove the edge (i, j) from the graph (from graph). If this causes the graph to have no outgoing edges graph[i], then we'll declare it eventually safe and add it to our queue.
这个算法还是很聪明的: 当你从一个safe的j地方出发, 向上找到了i, 那么只要你要检查的是当我把ij这条path给remove掉之后, i剩下的edge是不是没有了; 当然了, 因为实际上有好多个sink, 以及safe的node, 所以最后这个要是一个循环操作: 当j把i的ij给remove之后, 如果i还有其他的out edge, 不代表i就有问题: 必须所有的j都处理完了之后, 如果还剩了i->?, 那么就是有问题了;
其实这个做法本质上有点像UF? 因为这题是多个sink, 所以最后估计让你写UF, 也是这样写;
所以这题的reversed adjacency list想到去做, 是一个很重要的思路;
Also, we'll keep track of everything we ever added to the queue, so we can read off the answer in sorted order later.
这个算法整体设计还算是比较复杂的了;
class Solution {
public List<Integer> eventualSafeNodes(int[][] G) {
int N = G.length;
boolean[] safe = new boolean[N];
List<Set<Integer>> graph = new ArrayList();
List<Set<Integer>> rgraph = new ArrayList();
for (int i = 0; i < N; ++i) {
graph.add(new HashSet());
rgraph.add(new HashSet());
}
Queue<Integer> queue = new LinkedList();
for (int i = 0; i < N; ++i) {
if (G[i].length == 0)
queue.offer(i);
for (int j: G[i]) {
graph.get(i).add(j);
rgraph.get(j).add(i);
}
}
while (!queue.isEmpty()) {
int j = queue.poll();
safe[j] = true;
for (int i: rgraph.get(j)) {
graph.get(i).remove(j);
if (graph.get(i).isEmpty())
queue.offer(i);
}
}
List<Integer> ans = new ArrayList();
for (int i = 0; i < N; ++i) if (safe[i])
ans.add(i);
return ans;
}
}
其实也不复杂;
hash for O(1) remove
算法本身设计的还是很完整优雅的, 尤其是你看出来没有, 他graph和rgraph里面为什么要用HashSet? 因为他后面有一个remove的操作, 这个在hash结构里面才能做到一个O(1)的复杂度, 这个也都是很多值得学习的小技巧;
如果不理解这个算法的正确性, 可以看下面这个图: 红圈代表被enqueue了, 然后红色数字代表被enqueue的次序(展示一个queue算法的trace画法):

可以看到4这个点比3后enqueue, 就是因为4有两个sink;
2018-05-01 19:25:13 这个算法如果自己写, 容易踩坑的一个地方在于, 比如我处理1, 然后处理2, 然后2处理完了之后, 我一看, 诶3是安全的, 然后这个时候我可能想着立刻很eager的把3的parent link也全都删了, 但是这样最后写出来的算法我感觉应该就没有他这里这个漂亮了;
当然, 也不是说这样做就一定不对; 但是如果在写之前对整个算法的思路清晰一点, 应该还是最好能避免这个eager process到底的思路比较好;
Approach #2: Depth-First Search [Accepted]
Intuition
As in Approach #1, the crux of the problem is whether you reach a cycle or not.
Let us perform a "brute force": a cycle-finding DFS algorithm on each node individually. This is a classic "white-gray-black" DFS algorithm that would be part of any textbook on DFS. We mark a node gray on entry, and black on exit. If we see a gray node during our DFS, it must be part of a cycle. In a naive view, we'll clear the colors between each search.
Algorithm
We can improve this approach, by noticing that we don't need to clear the colors between each search.
When we visit a node, the only possibilities are that we've marked the entire subtree black (which must be eventually safe), or it has a cycle and we have only marked the members of that cycle gray. So indeed, the invariant that gray nodes are always part of a cycle, and black nodes are always eventually safe is maintained.
In order to exit our search quickly when we find a cycle (and not paint other nodes erroneously), we'll say the result of visiting a node is true if it is eventually safe, otherwise false. This allows information that we've reached a cycle to propagate up the call stack so that we can terminate our search early.
2018-05-01 19:28:57 这个逻辑跟我反过来的, 我的true是没有cycle, 他的true是有cycle;
另外你看他这个写法最后不需要sort;
class Solution {
public List<Integer> eventualSafeNodes(int[][] graph) {
int N = graph.length;
int[] color = new int[N];
List<Integer> ans = new ArrayList();
for (int i = 0; i < N; ++i)
if (dfs(i, color, graph))
ans.add(i);
return ans;
}
// colors: WHITE 0, GRAY 1, BLACK 2;
public boolean dfs(int node, int[] color, int[][] graph) {
if (color[node] > 0)
return color[node] == 2;
color[node] = 1;
for (int nei: graph[node]) {
if (color[node] == 2)
continue;
if (color[nei] == 1 || !dfs(nei, color, graph))
return false;
}
color[node] = 2;
return true;
}
}
2018-05-01 19:32:29 过一段时间重新看这个算法, 感觉还是挺复杂的, 一个难点在于, 他这里最后实际上DFS完成的是一个返回值和mutation协同配合的操作: 返回值本身并不是最后DFS的效果的主要部分;
DFS最后主要的效果实际上是保存在mutation也就是color这个数组里面的; 然后返回值本身只是为了让你能够对涂色有一个正确的判断;
理解我上面的意思, 你就应该能够理解, 他这个算法的核心, 就是要保证最后DFS能够走遍整个graph, 而不是跟我的思路一样, 看到cycle就拍屁股就跑; 当然代码看起来是很想, 但是他DFS里面的那个return false实际上就是一个保留涂色的核心操作;
两个算法的复杂度都是O(V+E);
again, 看这里这个DFS函数的时候, 先不要看base case, 这个讲了很多遍了;
这个color是怎么定义的我不太清楚了, 好像跟BFS的不太一样; 那么就直接看代码, color在哪里改了: 开始之前先gray, 然后最后所有的child都处理完了之后, 实际上也就是subtree rooted at this node都处理完了之后, 就black, 所以color的大概意思就清楚了;
更进一步, gray实际上就是在标记一个path: 你自己想一下DFS的执行顺序就知道了;
这里的color不清除的思路还是挺聪明的, 因为如果一个DFS能够成功退出, 那么...好像没想清楚;
为了方便理解这个算法, 我就只考虑每一个node的branching只有1的情况, 也就是要么是line, 要么是cycle, 反正这个也足够用来理解这个问题了;
这个算法其实还是看了一段时间的, 仔细思考一下visual, 他这个设计其实是挺好的; CLRS上面的三色思路, 这里是第一次看到实现; 实现本身其实确实并不是很难; 不过这题其他他是把这个算法给重新设计了一次, 为了应付这道题本身, 这个算法的改写还是有点嚼头的:
- 你看他一旦碰到cycle之后, 直接立刻return false, 那么这个带来的结果, 就是这个node的灰色保留了; 而且因为这里是一个直接的向上传递, 走到这个灰色node的path上的所有node(其实也就是cycle上的node)的灰色全都保留了; 2018-05-01 19:35:33 没有错, 他这个DFS代码本身也是有一个premature exit的, 但是这种设计的时候, 你就要想清楚, 你到底是true的时候快跑, 还是FALSE的时候快跑; 这里true的时候(也就是能碰到黑色的时候)反而不能拍屁股走人; 这个是理解这个算法很subtle的一个地方; 我举一个例子, 比如我们在i, 然后他有三个child, 分别是nei1, nei2, nei3, 然后nei1可以走到黑色部分, 是安全的, nei2会走到i的parent, 所以是cycle, nei3也是可以走到黑色; 那么我们nei1走完之后, dfs (nei1) return true, 这个时候是不能立刻逃跑的, 而是必须要继续走nei2, return false, 这个时候我们保留i的涂色是gray, 然后就逃跑了; 你可能会问, nei3怎么办? 无所谓啊, i能够通过nei2走到cycle, 那么i就定性了, nei3能走到哪儿, 即使nei3也能走到一个cycle, 也无所谓了; 这个算法最后用这个逻辑完成了一个类似memo的操作;
- 相反, 假如还是按照正常的DFS涂色的顺序, 你走到了一个sink, 然后开始回退上行(退出的时候涂黑), 那么这个时候就有一个类似sink在开始扩张的感觉: 对应的实际上就是类似于被sink给感染的黑色区域在扩张的过程;
总体来说我认为这个算法的设计本身是比我的复杂的, 尤其是这个灰色保留的思路. 当然了, 也许就是我自己没有见识过而已. 看样子用DFS来做各种类似cycle detection的常规任务的时候, 怎么设计这个涂色思路, 是一个关键;
我这个直接用backtrack来维护path的相对来说就有点投机取巧了; 2018-05-01 19:38:43 当然, 必须要想到加memo之后才能做到和他相当的速度;
另外, 了解这个涂色之后, 应该就知道这题BFS肯定也能写了; 当然不代表下面的contest写法就一定是这么写的, 这会儿我还不知道;
In Approach #2, Why do we need to skip current iteration while traversing the neighbors ? I attempted the code without
if (color[node] == 2) continue;and it got accepted
这个评论是因为awice这个代码实际上是有冗余的, 他在leaf和preleaf的位置都判断了一个黑色neighbor的情况; 所以这个人把这个preleaf的位置的判断给删除了之后, 最后仍然保证对于黑色的child能够有正确的处理;
value of color represents three states:
0:have not been visited
1:safe
2:unsafe
For DFS,we need to do some optimization.When we travel a path,we mark the node with 2 which represents having been visited,and when we encounter a node which results in a cycle,we return false,all node in the path stays 2 and it represents unsafe.And in the following traveling,whenever we encounter a node which points to a node marked with 2,we know it will results in a cycle,so we can stop traveling.On the contrary,when a node is safe,we can mark it with 1 and whenever we encounter a safe node,we know it will not results in a cycle.
class Solution {
public List<Integer> eventualSafeNodes(int[][] graph) {
List<Integer> res = new ArrayList<>();
if(graph == null || graph.length == 0) return res;
int nodeCount = graph.length;
int[] color = new int[nodeCount];
for(int i = 0;i < nodeCount;i++){
if(dfs(graph, i, color)) res.add(i);
}
return res;
}
public boolean dfs(int[][] graph, int start, int[] color){
if(color[start] != 0) return color[start] == 1;
color[start] = 2;
for(int newNode : graph[start]){
if(!dfs(graph, newNode, color)) return false;
}
color[start] = 1;
return true;
}
}
跟editorial2一样的做法; 颜色定义稍微改变了一下;
2018-05-01 19:41:04 如果太纠结DFS返回值本身的含义, 可能会迷失掉这个算法的内涵; 实际上最好还是用有没有cycle来理解这个返回值; 他这里也是一看到有cycle(subtree rooted at newNode has cycle, return false)就立刻逃跑, 然后有这个保留涂色的操作; 这个保留涂色最后就是完成了跟我的memo一样的操作: 一个cycle不要反复的去探索; 他最后代码还是比awice简练不少;
This is equal to find nodes which doesn’t lead to a circle in any path.
We can solve it by walking along the path reversely.
- Find nodes with out degree 0, they are terminal nodes, we remove them from graph and they are added to result
- For nodes who are connected terminal nodes, since terminal nodes are removed, we decrease in-nodes’ out degree by 1 and if its out degree equals to 0, it become new terminal nodes
- Repeat 2 until no terminal nodes can be found.
Here is my 300ms 20-line Python Code:
def eventualSafeNodes(self, graph):
"""
:type graph: List[List[int]]
:rtype: List[int]
"""
n = len(graph)
out_degree = collections.defaultdict(int)
in_nodes = collections.defaultdict(list)
queue = []
ret = []
for i in range(n):
out_degree[i] = len(graph[i])
if out_degree[i]==0:
queue.append(i)
for j in graph[i]:
in_nodes[j].append(i)
while queue:
term_node = queue.pop(0)
ret.append(term_node)
for in_node in in_nodes[term_node]:
out_degree[in_node] -= 1
if out_degree[in_node]==0:
queue.append(in_node)
return sorted(ret)
看起来跟editorial1差不多哈;
UNFINISHED
contest: 干净利落的BFS做法:
class Solution {
public List<Integer> eventualSafeNodes(int[][] graph) {
List<Integer> ans=new ArrayList<>();
List<List<Integer>> in=new ArrayList<>();
Queue<Integer> q=new ArrayDeque<>();
int n=graph.length;
int[] out=new int[n];
for (int i=0;i<n;i++) in.add(new ArrayList<>());
for (int i=0;i<n;i++)
{
out[i]=graph[i].length;
for (int j:graph[i])
{
in.get(j).add(i);
}
}
for (int i=0;i<n;i++)
if (out[i]==0) q.add(i);
while (!q.isEmpty())
{
int x=q.poll();
ans.add(x);
for (int y:in.get(x))
{
out[y]--;
if (out[y]==0) q.add(y);
}
}
Collections.sort(ans);
return ans;
}
}
不是BFS, 别瞎说, 这个就是跟E1一样的做法; 都是queue算法所以看起来类似而已;
Problem Description
In a directed graph, we start at some node and every turn, walk along a directed edge of the graph. If we reach a node that is terminal (that is, it has no outgoing directed edges), we stop.
Now, say our starting node is eventually safe if and only if we must eventually walk to a terminal node. More specifically, there exists a natural number K so that for any choice of where to walk, we must have stopped at a terminal node in less than K steps.
Which nodes are eventually safe? Return them as an array in sorted order.
The directed graph has N nodes with labels 0, 1, ..., N-1, where N is the length of graph. The graph is given in the following form: graph[i] is a list of labels j such that (i, j) is a directed edge of the graph.
Example:
Input: graph = [[1,2],[2,3],[5],[0],[5],[],[]]
Output: [2,4,5,6]
Here is a diagram of the above graph.
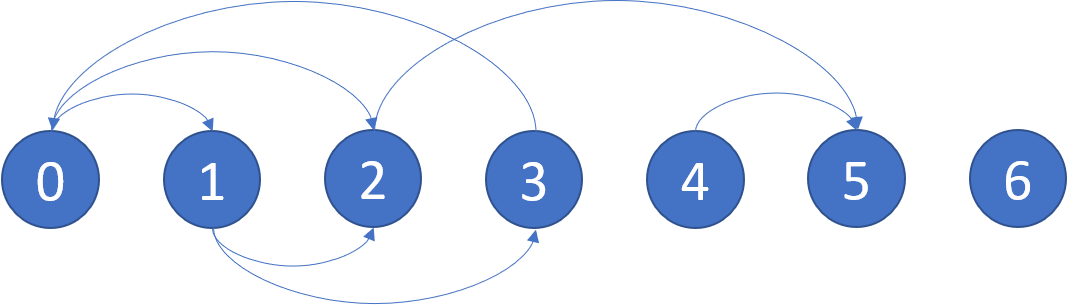
Note:
- graph will have length at most 10000.
- The number of edges in the graph will not exceed 32000.
- Each graph[i] will be a sorted list of different integers, chosen within the range [0, graph.length - 1].
Difficulty:Medium
Total Accepted:1.2K
Total Submissions:4K
Contributor:awice
Companies
google
Related Topics
depth-first searchgraph